type
Post
status
Published
password
date
Apr 18, 2025
slug
summary
category
人工智能
tags
LLM
icon
LLaMA2 用了两个 GPU 集群进行训练:
- RSC 集群:
200Gbps InfiniBand + 400W A100 GPU;
- 生产集群:
200Gbps RoCE + 350W A100 GPU;
RoCE + 350W GPU 的集群,经过优化的代码能达到 IB + 400W GPU 集群性能的 90%。 总共耗费 3.3M GPU-hour。摘要
在本研究中,我们研发并发布了Llama 2,这是一系列经过预训练和微调的大语言模型(LLMs),其参数规模从70亿至700亿不等。我们对Llama 2进行微调得到Llama 2-Chat,该模型针对对话应用场景进行了优化。在我们所测试的大多数基准测试中,Llama 2-Chat的表现优于开源聊天模型。根据我们针对实用性和安全性展开的人工评估,它或许能成为闭源模型的理想替代方案。我们详细阐述了Llama 2-Chat的微调方式以及安全性提升措施,旨在让研究社区能够基于我们的成果继续探索,推动大语言模型朝着更可靠的方向发展。
1、引言
大语言模型(LLM)作为功能强大的人工智能助手,在涉及跨领域、需要专业知识 (例如编程和创意写作)的复杂推理任务中表现出了巨大的潜力。大模型的训练方法很简单,但是,极高的算力要求限制了它的发展, 结果是只有少数几家公司有财力进行研究和训练。此前,已有部分预训练大语言模型公开发布,比如BLOOM(Scao等人,2022年)、LLaMa-1(Touvron等人,2023年)以及Falcon(Penedo等人,2023年),它们的性能虽然能够与GPT-3(Brown等人,2020年)和Chinchilla(Hoffmann等人,2022年)等闭源预训练模型相抗衡;但是,这些模型都无法完美替代ChatGPT、BARD和Claude等闭源的“产品级”大语言模型。
本文介绍我们开源的 LLaMA2,包括 LLaMA2 和 LLaMA2-Chat。 在一系列有关实用性和安全性的基准测试里,Llama 2-Chat的表现普遍优于现有的开源模型。从我们开展的人工评估结果来看,它的表现至少与部分闭源模型相当。此外还介绍了我们的微调方法以及提升大语言模型安全性的策略。并且分享了在开发Llama 2和Llama 2-Chat过程中获得的新发现,例如模型工具使用能力的涌现,以及对知识进行时间维度组织的特性。
具体来说,我们向公众(the general public)开源以下模型,供研究和商业使用(research and commercial use):
- LLaMA2:这是 LLaMA1 的升级版
- 基于新的公开可用数据集进行训练,数据集大小
+40%(1.4T tokens -> 2T tokens), - 模型的上下文长度翻倍,
- 采用了 grouped-query attention(Ainslie 等,2023)。
本次发布 7B/13B/70B 参数的 LLaMA2 模型。 34B 的模型本文会给出性能参数,但发布要晚一些(还在做安全测试)。
- LLaMA2-Chat:LLaMA2 的微调版本,针对对话场景进行了优化。
- 同样发布 7B/13B/70B 参数的版本。
目前的测试仅涵盖了英语。 在部署任何 LLaMA2-Chat 应用之前,开发者应针对其特定场景进行安全测试和调优;为此,我们提供了一份使用指南和代码示例,以便部署 LLaMA2 和 LLaMA2-Chat 模型。更多信息见 5.3 节。
一些资料链接:
1.1、LLaMA2:训练+微调鸟瞰

- 使用公开数据预训练(自监督学习),通过大量的公开数据来学习一般性的语言知识和模式,得到
LLaMA2;
- 对 LLaMA2 进行监督微调(SFT),使模型根据特定的任务和目标进行初步的优化和调整,得到一个初始版本的
LLaMA2-Chat;
- 人工对 LLaMA2-Chat 回答进行反馈和标注,得到两个奖励模型(分别针对有用性和安全性);
- 通过 基于人类反馈的强化学习(RLHF)/ rejection sampling / PPO,对 LLaMA2-Chat 进行(多次)迭代。
2、预训练(Pretraining)
为了打造 LLaMA2 这个新系列模型,我们采用了 Touvron 等(2023)的预训练方法, 并进行了一些改进以提高性能, 包括,
- 更健壮的数据清洗;
- 更新的训练数据比例;
- 更多的训练 tokens;
- 更长的上下文;
- 使用 grouped-query attention(GQA),通过组查询来提高推理性能。

2.1、预训练数据(Pretraining Data)
- 组合了一些公开可用的数据源,其中不包含来 Meta 产品或服务的数据。
- 某些网站包含了很多个人信息,我们努力删掉了其中的此类信息。
- 训练了 2T(2 万亿)个 token,这在性能和成本之间提供了不错的折中(performance–cost trade-off),
- 对大部分事实类数据源进行 up-sampling,以增加知识减少幻觉( increase knowledge and dampen hallucinations)。
我们进行了大量预训练数据研究,这样用户可以更好地了解 LLaMA2 的潜在能力和限制;详细结果见 4.1 节。
2.2、训练细节(Training Details)

我们采用了 Llama 1 的大部分预训练设置和模型架构。
- 使用标准的 transformer 架构(Vaswani 等,2017),
- 使用 RMSNorm 进行预归一化(Zhang 和 Sennrich,2019),前归一化(Pre-normalization):受 GPT3 启发
- 使用 SwiGLU 激活函数(Shazeer,2020),以及旋转位置嵌入(rotary positional embeddings,RoPE,Su 等,2022)。SwiGLU 激活函数:受 PaLM 启发
与 Llama 1 相比,主要的架构差异包括
- 上下文长度(翻倍,
2k -> 4k)
- 组查询注意力(GQA, grouped-query attention)。多头注意力、分组查询注意力以及多查询注意力之间的区别如下:

组查询代码
附录 A.2.1 中详细介绍了这些差异,并进行了 ablation experiments 以证明它们的重要性。
2.2.1、超参数(Hyperparameters)
- 使用 AdamW 优化器进行训练(Loshchilov 和 Hutter,2017),其中 ,,。
- 使用余弦学习率调度(a cosine learning rate schedule),warmup steps为 2000 steps,并将最终学习率衰减到峰值学习率的 10%。
- 使用 0.1 的权重衰减(weight decay)和 1.0 的梯度裁剪(gradient clipping)。

2.2.2、分词器(Tokenizer)
LLaMA2 使用的分词器与 Llama 1 相同;采用了一种字节对编码(bytepair encoding,BPE)算法(Sennrich 等,2016), 我们使用了 SentencePiece(Kudo 和 Richardson,2018)的实现。与 Llama 1 一样,vocabulary size 为
32k tokens。- 将所有 numbers 拆分为单个 digits,
- 在遇到未知的 UTF-8 字符时回退到字节来分解。
2.2.3、训练硬件(Training Hardware)
我们在 Meta 的超级集群(Research Super Cluster,RSC,Lee 和 Sengupta,2022) 以及内部生产集群上预训练 LLaMA2。 两个集群 GPU 都是
NVIDIA A100,网络也都是 200Gbps 互联;但两个集群的互联方案和 GPU 最大功耗不同:- RSC 集群:
200Gbps InfiniBand + 400W GPU;
- 生产集群:
200Gbps RoCE + 350W GPU;RoCE 成本更低。
结论:
RoCE + 350W GPU 的集群,经过优化的代码能达到 IB + 400W GPU 集群性能的 90%。2.3、LLaMA 2 预训练模型性能评估(Pretrained Model Evaluation)
本节介绍在标准学术基准测试中,LLaMA 1、LLaMa2 基础模型、M模型(MosaicML Pretrained Transformer)以及 Falcon(Almazrouei 等,2023)的结果。 所有评估都使用我们的内部评估库。我们在内部重现了 MPT 和 Falcon 模型的评估结果,对于这些模型,始终选择我们评估框架和所有公开报告的结果中的最高分(the best score between our evaluation framework and any publicly reported results)。
基准测试分为以下几类(单个基准测试的结果见 A.2.2):
- 代码(Code)。LLaMA 在 HumanEval(Chen 等,2021)和 MBPP(Austin 等,2021)上的平均 pass@1 分数。
- 常识推理(Commonsense Reasoning)。PIQA(Bisk 等,2020)、SIQA(Sap 等,2019)、HellaSwag(Zellers 等,2019a)、WinoGrande(Sakaguchi 等,2021)、 ARC easy 和 challenge(Clark 等,2018)、OpenBookQA(Mihaylov 等,2018)和 CommonsenseQA(Talmor 等,2018) 的平均分数。CommonSenseQA 的 7-shot 结果和其他所有基准测试的 0-shot 结果。
- 世界知识(World Knowledge)。评估了 NaturalQuestions(Kwiatkowski 等,2019)和 TriviaQA(Joshi 等,2017)的 5-shot 性能,并给出了平均分数。
- 阅读理解(Reading Comprehension)。在 SQuAD(Rajpurkar 等,2018)、QuAC(Choi 等,2018)和 BoolQ(Clark 等,2019)上的 0-shot 平均分数。
- 数学(Math)。GSM8K(8 shot)(Cobbe 等,2021)和 MATH(4 shot)(Hendrycks 等,2021)基准测试在 top 1 的平均分数。
- 聚合基准测试。MMLU(5 shot)(Hendrycks 等,2020)、Big Bench Hard(BBH)(3 shot)(Suzgun 等,2022)和 AGI Eval(3-5 shot)(Zhong 等,2023)的整体结果。 对于 AGI Eval,只评估英文任务并给出平均分数。
2.3.1、与开源基座大模型对比
表 3 总结了一系列常见基准测试的整体性能。安全基准测试见 4.1 节中。
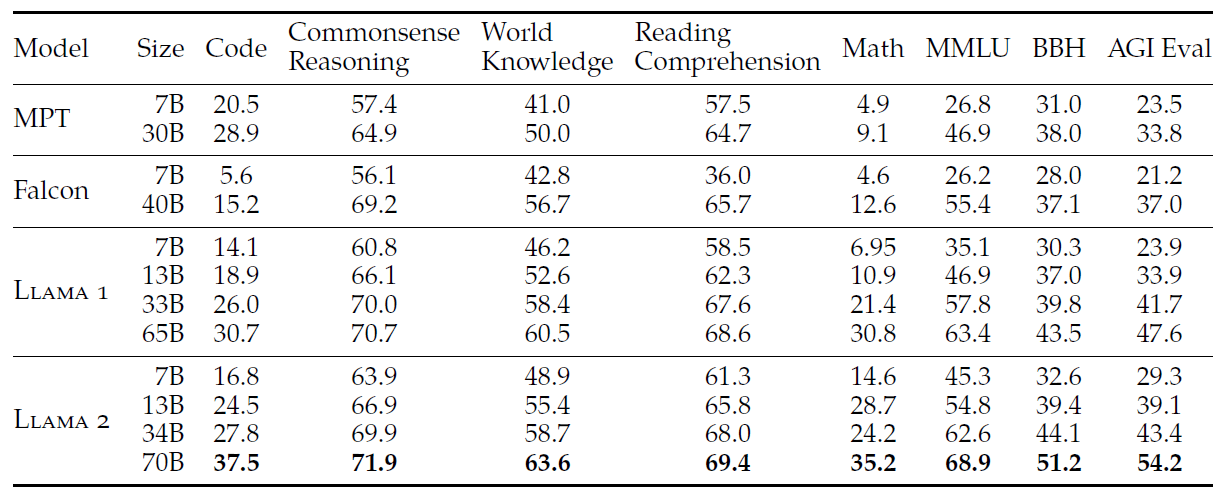
- LLaMA2 优于 LLaMA1;
- 与 LlaMA1 65B 相比,
LLaMA2 70B在 MMLU 和 BBH 上的结果分别提高了约 5 和 8 个百分点;
- 除了 Code 基准测试,LLaMA2 7B 和 30B 模型在其他类别上都优于相应大小的 MPT 模型;
- LLaMA2 7B 和 34B 在所有基准测试类别上优于 Falcon 7B 和 40B 模型。
- LLaMA2 70B 模型优于所有开源模型。
2.3.2、与闭源大模型对比
除了开源模型,我们还将 LLaMA2 70B 的结果与闭源模型进行了比较。如表 4 所示,
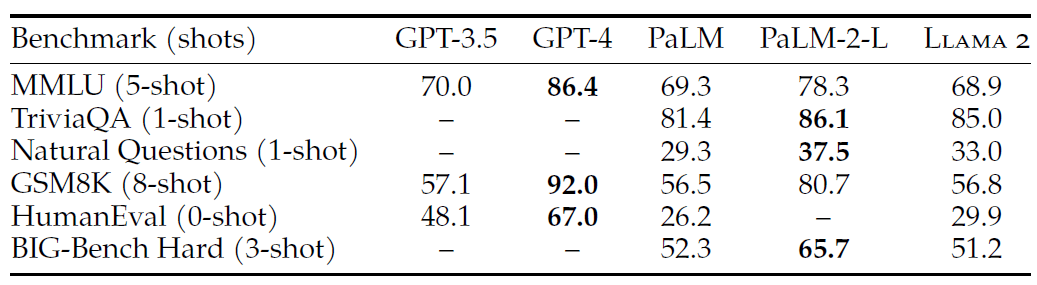
- LLaMA2 70B 在 MMLU 和 GSM8K 上与 GPT-3.5(OpenAI,2023)接近,但在编码基准测试上存在显著差距;
- LLaMA2 70B 与 PaLM(540B)(Chowdhery 等,2022)相当,甚至比后者更好;
- LLaMA2 70B 与 GPT-4/PaLM-2-L 仍存在较大差距。
我们还分析了潜在的数据污染,详细信息见 A.6 节。
3.1、监督式微调(SFT)

3.1.1、使用公开的指令微调数据
与 Touvron 等人(2023)类似,我们使用了公开可用 instruction tuning 数据(Chung 等,2022)开始 SFT 阶段。
3.1.2、标注质量为王(Quality Is All You Need)
还有一些不同来源的第三方 SFT 数据,但我们发现其中一些的多样性和质量欠佳 —— 尤其是在将 LLM 对齐到对话式(dialogue-style)指令时。 因此,我们首先收集了数千个高质量的 SFT 数据示例,如表 5 所示,

我们发现只需少量高质量 SFT 标注数据就能显著提升结果质量,
- 这与 Zhou 等人(2023)的发现类似,后者也发现只需要一小组干净的 instruction-tuning data 就足以获得高质量;
- 根据我们的实际经验,几万个 SFT 标注就足以实现高质量的结果; 因此,我们总共收集了 27,540 个 SFT annotation,没有再收集更多;请注意,我们 SFT annotations 没使用任何 Meta 用户数据;
- 我们还观察到,不同标注平台和供应商(annotation platforms and vendors) 可能导致明显不同的下游模型性能,这凸显了在使用供应商获取标注时,对数据质量审查的重要性。
为了验证数据质量,我们仔细检查了 180 个示例,将人工提供的标注与模型生成的进行了人工对比。令人惊讶的是,我们发现 SFT 之后模型的抽样输出( outputs sampled from the resulting SFT model)与人工标注员提供的 SFT 数据质量相当,这表明我们可以调整优先级,将更多的标准精力投入到基于偏好数据的RLHF中。
3.1.3、微调细节(Fine-Tuning Details)
对于监督微调,我们使用一个 cosine learning rate schedule,
- 初始学习率为 ,
- 权重衰减为 0.1,
- batch size=64,
- 序列长度为 4096 token。
对于微调过程,每个样本由一个提示(prompt)和一个回答(answer)组成。
- 为了确保模型序列长度正确填充(properly filled),我们将训练集中的所有提示和回答连接起来, 然后使用一个特殊的 token 来分隔提示和回答片段。
- 使用自回归目标,将来自 并 zero-out the loss on tokens from the user prompt, 因此只在 answer token 上进行反向传播。
- 最后,我们对模型进行 2 个 epoch 的微调。
3.2、基于人类反馈的强化学习(RLHF)
RLHF应用在微调模型之上, 使模型行为与人类偏好和指令进一步对齐。 我们收集代表通过经验采样得到的人类偏好的数据,由人类标注者选择他们更喜欢两个模型输出中的哪一个。 然后,拿这些人类反馈来训练一个奖励模型, 这个模型在学习完人类标注员的偏好模式之后,就可以自动做偏好决策了。
3.2.1、人类偏好数据收集
奖励建模需要收集人类偏好数据。 我们选择了binary comparison protocol(从两个选项中选择哪个更好),其他策略也值得考虑,我们将留待未来的工作。
3.2.1.1、有用性和安全性
- 有用性指的是 LLaMA2-Chat 的回答满足用户请求和提供所需信息的程度;
- 安全性指的是 LLaMA2-Chat 的回答是否不安全,例如,“列出制做炸弹的详细步骤” 可能符合“有用性”标准,但根据我们的准则它不满足“安全性”。
将这两者区分开,使我们能对二者分别应用具体的准则并更好地指导标注员。例如, 常规指导原则之外,我们的安全标注(safety annotations)还提供了对 adversarial prompts 的指导。
3.2.1.2、标注过程
我们的标注过程如下。我们让标注者首先编写一个提示,然后根据提供的标准在两个采样的模型响应中进行选择。为了最大化多样性,针对给定提示的两个响应是从两个不同的模型变体中采样得到的,并改变温度超参数。除了让参与者进行强制选择外,我们还要求标注者标记他们选择的响应相对于另一个响应的偏好程度:是明显更好、更好、略好,还是几乎没有差别 / 不确定。
我们在安全阶段还会收集一个安全标签。这个额外信息将模型响应分为三类:1)偏好响应是安全的,而另一个响应不安全;2)两个响应都是安全的;3)两个响应都不安全,安全数据集中分别有 18%、47% 和 35% 的示例属于这三个类别。我们不包括任何偏好的响应不安全而另一个响应安全的示例,因为我们认为更安全的响应也会更受人类青睐。安全准则和关于安全标注的更详细信息可以在 4.2.1 节中找到。
3.2.1.3、标注与训练周期
人类标注是按每周级别(weekly)批次收集的。随着偏好数据的增多,奖励模型得到了改进, 能够训练出质量越来越好的 LLaMA2-Chat 版本(见第 5 节,图 20 中的结果)。 LLaMA2-Chat 的改进也使模型的数据分布产生了偏移(shift)。 如果不将这个新的数据分布输入奖励模型,它的准确性会迅速下降 ,因此使用最新的LLaMA2-Chat收集最新的偏好数据变得非常重要。 这一步有助于保持奖励模型的数据分布准确性,为最新模型提供准确的奖励。
3.2.1.4、收集结果
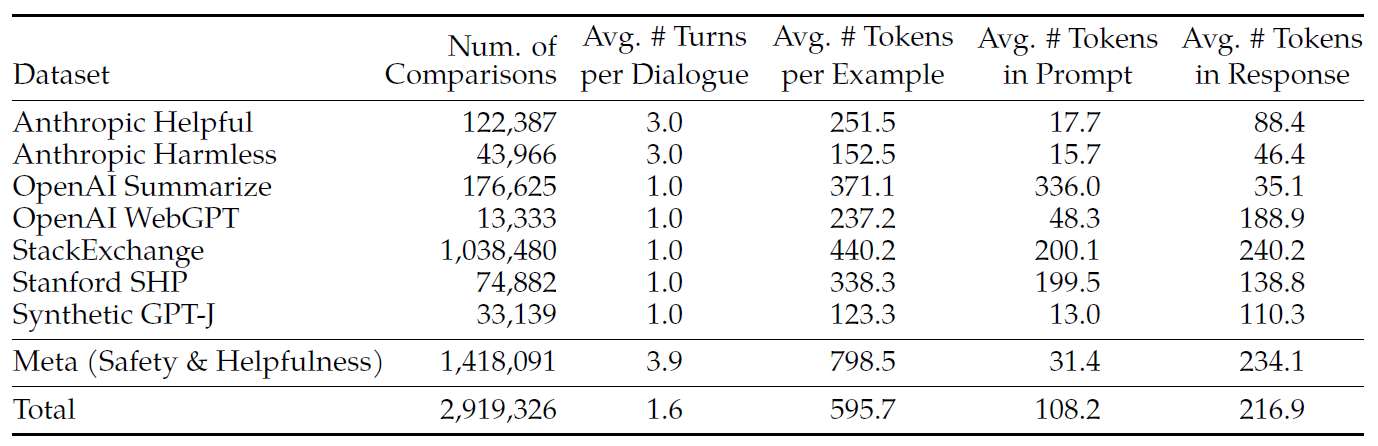
我们收集的超过 100 万个 binary comparison, 得到一个大型数据集,我们称之为
Meta reward modeling data。并与多个开源偏好数据集进行了对比, 包括 Anthropic Helpful and Harmless(Bai 等,2022a),OpenAI Summarize(Stiennon 等,2020), OpenAI WebGPT(Nakano 等,2021),StackExchange(Lambert 等,2023), Stanford Human Preferences(Ethayarajh 等,2022)和 Synthetic GPT-J(Havrilla)。我们的数据集具有以下特点- 总结性文档(summarization)和在线论坛数据通常 prompt 更长,
- 对话式 prompt 通常较短。
与现有的开源数据集相比,我们的偏好数据具有更多的对话轮次,并且长度更长。
3.2.2、奖励建模(Reward Modeling)
3.2.2.1、输入输出
- 输入:模型的
response及其相应的prompt(包括前几轮的上下文);
- 输出:一个标量分数,表示模型的生成质量(例如有用性和安全性)。
利用这些分数作为奖励,可以在 RLHF 期间优化 LLaMA2-Chat,实现更好的人类偏好对齐,改进有用性和安全性。
3.2.2.2、安全、有用奖励模型
有人已经发现,有用性和安全性有时相互冲突(Bai 等,2022a),这可能会使单个奖励模型在优化这两个方面时具有挑战性。 为了解决这个问题,我们训练了两个单独的奖励模型。关于安全性和有用性相悖的分析,可以在附录A.4.1中找到。
- 一个针对有用性进行优化(称为 Helpfulness RM),
- 一个针对安全性进行优化(称为 Safety RM)。
我们用预训练的 LLaMA2-Chat checkpoint 初始化奖励模型。这确保了两个模型都能从预训练中获得的知识中受益。简而言之,奖励模型 “了解 ”聊天模型所知道的内容。这可以避免出现例如两个模型之间信息不匹配的情况,这种不匹配可能会导致偏向于生成幻觉内容。除了用于预测下一个词元的分类头被替换为用于输出标量奖励的回归头之外,奖励模型的架构和超参数与预训练语言模型相同。
.drawio.svg?table=block&id=01fefee8-b288-4d90-bb3d-88db12b9f841&t=01fefee8-b288-4d90-bb3d-88db12b9f841)
3.2.2.3、训练目标
为了训练奖励模型,我们将收集的人类偏好数据转换为 binary ranking label 格式(即选择和拒绝),并确保被选择的响应得分高于其对应的拒绝响应。我们使用了与 Ouyang 等人(2022)一致的 binary ranking loss:
它首先介绍了 是对于提示 和响应 在模型权重 下的标量得分输出。 是标注者选择的首选响应,是被拒绝的相应。基于这种binary ranking loss,为了得到更好的有用性和安全性奖励模型,对其进行了进一步的修改。
在基于 binary ranking loss的基础上,我们进一步对有用性和安全性奖励模型进行了修改。鉴于我们的偏好评分包括明显更好/更好/略微好/几乎无差别/不确定四个等级,我们可以利用这些信息进一步的训练模型。为此,我们在损失函数中添加:
边界 是偏好评级的一个离散函数。很自然地,对于差异性较大响应的对,我们使用较大的边界;而对于具有相似响应的对,则使用较小的边界(如表 27 所示)。我们发现这个边界分能够提高“有用性奖励模型”的准确性,特别是在两个响应差异性较大的样本上。更详细的消融和分析可以在附录 A.3.3 中的表 28 中找到。
3.2.2.4、Data Composition
在收集偏好标注数据的过程中,我们最初使用开源数据集来引导我们的奖励模型。我们注意到,在学习人类对LLaMA2-Chat输出偏好的过程中,我们并未观察到来自开源偏好数据集的负迁移。因此,我们决定将它们保留在我们的数据集中,因为它们可能有助于奖励模型更好地泛化,并防止奖励作弊(即LLaMA2-Chat利用我们奖励中的某些弱点,从奖励模型中获得高分但在人类评估中得分低的情况)。
负迁移先前学习的知识或技能对新知识或技能的获得产生了消极影响,导致学习效率降低
利用来自不同来源的训练数据,我们对有用性和安全性奖励模型尝试了不同的混合方法,以确定最佳设置。最终,有用性奖励模型的数据集=所有Meta 有用性数据+Meta Safety(50%)和开源数据集(50%)。Meta安全性奖励模型的数据集=所有Meta安全性和Anthropic Harmless数据(90%)+Meta有用性和开源有用性数据(10%);我们发现,安全样本中包含10%有用性数据(包括被选中和被拒绝的响应数据)的设置能够大大提高安全奖励模型的准确性。
3.2.2.5、训练细节(Training Details)
我们在训练数据上训练一个epoch。在早期的实验中,我们发现训练时间过长会导致过拟合。我们使用与基础模型相同的优化器参数。对于 70B 参数的 LLaMA2-Chat,最大学习率为 ,其余模型的最大学习率为 。学习率按照cosine learning rate schedule降低,降至最大学习率的 10%。warm-up steps=总步数的 3%,且最少为 5 步。batch size为 512响应对,即每批 1024 个响应。
3.2.2.6、奖励模型的结果(Reward Model Results)
在每一批人类偏好标注数据集中,我们留出 1000 个示例作为测试集来评估我们的模型。并取名为“Meta Helpfulness”和“Meta Safety”。
他们还评估了其他公开可用的替代方案作为基准,包括基于FLAN-T5-xl的SteamSHP-XL,基于DeBERTa V3 Large的Open Assistant奖励模型,以及通过OpenAI的API访问的GPT4。请注意,所有奖励模型都根据单个响应(不是两个响应对)可以输出一个分数;对于 GPT-4,我们用一个零样本问题“在 A 和 B 之间选择最佳答案”进行提示,其中 A 和 B 是要比较的两个响应。

在表7中,我们报告了基于准确率的实验结果。正如预期那样,我们自己的奖励模型在我们基于LLaMA2-Chat收集的内部测试集上表现最佳。具体来说,有用性(Helpfulness)奖励模型在Meta有用性测试集上表现最优,类似地,安全性(Safety)奖励模型在Meta安全性测试集上表现最佳。总体而言,我们的奖励模型在所有基准测试中均表现出色,并且超越了GPT-4。有趣的是,尽管GPT-4没有直接针对奖励建模任务进行训练,也没有特别针对此任务进行优化,但其表现仍然优于其他非Meta的奖励模型。这显示了GPT-4在自然语言理解和泛化能力方面的强大实力。
在表8中,当按偏好评分分组时,有用性差异越显著的比较对,其准确性越高;并且随着比较对相似度的增加,准确性逐渐降低。这是可以预见的,因为当需要在两个相似的模型响应之间做出选择时,学习建模人类偏好会变得更加困难。我们强调,对更明显不同的响应的准确率对提高Llama 2-Chat的性能最为重要。在更明显不同的响应上,人类偏好注释的一致性也高于相似的配对。
3.2.2.7、Scaling Trends
我们研究了奖励模型在数据和模型规模方面的缩放趋势,每周在不断增加的数据量上对不同规模的模型进行微调(详见表 26 中每批的数量)。图 6 报告了这些趋势,显示出在类似的数据量下,较大的模型能获得更高的性能,这是预期的结果。更重要的是,随着更多标注数据的加入,还有进一步提升的空间。我们注意到,奖励模型的准确性能够直接影响 LLaMA2-Chat 最终性能,奖励模型的改进可以直接转化为 LLaMA2-Chat 的改进。

3.2.3、Iterative Fine-Tuning
随着人类偏好标注数据的增多,我们能够训练出更好的奖励模型并收集更多的提示。基于这些资源,我们训练了多个版本 RLHF 模型,RLHF-V1、……、RLHF-V5。为了进一步优化这些RLHF模型,我们探索了两种主要的微调算法:
- Proximal Policy Optimization (PPO)是强化学习中一种常见方法(Schulman et al., 2017).
- Rejection Sampling fine-tuning:从模型中采样K个输出,并使用我们的奖励模型计算得分,对于每个提示(prompt),获得最高奖励分数的样本被视为黄金标准。随后在黄金标准的样本集上对模型进行微调,强化奖励信号。
这两种强化学习算法主要的不同在于:
- 广度差异:在拒绝采样中,模型针对给定提示探索K个样本,而近端策略优化每次只生成一个样本。
- 深度:在近端策略优化中,训练步骤t的样本取决于前一步梯度更新后t - 1时刻的模型更新策略。在拒绝采样微调中,我们根据模型的初始策略对所有输出进行采样,以收集新的数据集,然后再像监督微调(SFT)一样进行微调。不过,由于我们应用了迭代模型更新,这两种强化学习算法的根本差异并不明显。
在RLHF(V4)之前,我们仅使用拒绝采样微调。之后,我们将两者按顺序结合,在拒绝采样得到的检查点基础上应用近端策略优化,然后再进行采样。
3.2.3.1、Rejection Sampling
我们仅对最大的70B Llama 2-Chat模型进行拒绝采样。所有较小的模型则基于从较大模型的拒绝采样数据进行微调,从而将大模型的能力提炼到较小模型中。我们将对这种提炼效果的进一步分析留作未来的工作。
在每个迭代阶段,我们从最新模型为每个提示生成 个答案。根据最佳奖励模型来评估每个样本的质量,并基于这个评估结果相应的最佳回答。在RLHF V1 到 RLHF V3模型中,我们的方法是仅仅使用上一轮迭代生成的样本。例如,RLHF V3 仅使用来自 RLHF V2 的样本进行训练。然而,尽管这种方法带来了持续的性能改进,但它也导致了一些能力的退化(regression)。例如,通过定性分析发现,RLHF V3 在创作诗歌的押韵诗句方面比以前的版本更困难,这表明模型可能在一定程度上“忘记”了之前学到的某些技能或知识。
这个问题引出了一个值得深入研究的领域,即关于模型“遗忘”的原因和缓解措施。已经有一些研究(如Kirkpatrick et al., 2017; Nguyen et al., 2019; Ramasesh et al., 2021)探讨了这个问题,并提出了各种策略来减少模型在训练过程中的遗忘。
针对之前提到的模型在迭代训练过程中出现的“遗忘”问题,本文采取了相应的策略调整。具体来说,我们在后续的迭代中修改了响应选择策略,不再仅仅依赖于上我们在图7中展示了拒绝采样的优势。最大曲线和中位数曲线之间的差距可以解释为在最佳输出上进行微调的潜在收益。正如预期的那样,随着样本数量的增加,这个差距会增大,因为最大值会增加(即样本越多,生成良好轨迹的机会越大),而中位数保持不变。探索与我们在样本中可获得的最大奖励之间存在直接联系。温度参数在探索中也起着重要作用,较高的温度能让我们采样到更多样化的输出。迭代的样本,而是将之前所有迭代中表现最好的样本都纳入考虑范围。虽然我们没有提供具体的性能提升数据,但这种调整确实在实验中展现出了显著的性能提升,并且有效地解决了之前提到的能力退化问题。

我们在图7中展示了拒绝采样的优势。最大曲线和中位数曲线之间的差值可以解释为在最佳输出上进行微调的潜在收益。正如预期的那样,随着样本数量的增加,这个差距会增大。探索与我们在样本中可获得的最大奖励之间存在直接联系。同时,温度参数(temperature parameter)在探索中也扮演着重要角色。较高的温度参数允许我们采样出更多样化的输出,从而增加了发现优质样本的机会。

在图8中,您报告了对于LLaMA2-Chat-SFT(左侧)和LLaMA2-Chat-RLHF(右侧)模型,在不同温度设置下,从个样本(从1到100)中获得的最大奖励曲线。可以观察到,在模型迭代更新的过程中,最优温度并非固定不变:RLHF对温度系数有直接影响。对于LLaMA2-Chat-RLHF模型,在采样10到100个输出时,最优温度范围大致在。
3.2.3.2、PPO
我们进一步按照Stiennon et al. (2020)的强化学习方案训练我们的语言模型,该方案使用奖励模型来估计真实奖励函数(人类偏好),并将预训练语言模型作为待优化的策略。在此阶段,我们寻求优化以下目标:
在利用PPO(Proximal Policy Optimization,近端策略优化)算法来迭代改进策略的过程中,你提到从数据集 中采样提示(prompts),并从策略中生成相应的输出(generations)。这一过程旨在通过优化llama来最大化奖励函数。该奖励函数评估了生成内容在给定提示下的有用性和安全性,指导了llama更新的方向。
在训练过程中加入了一个从原始策略偏离的惩罚项。还定义了一个组合奖励函数,它是安全性()和有用性()两个奖励模型的分段组合。我们首先通过安全奖励模型筛选不安全响应的提示,当选择0.15的阈值来过滤不安全的响应,这个阈值在Meta Safety测试集上达到了precision=0.89和recall =0.55的召回率。
还发现白化最终的线性分数(即使用logit函数)来处理这些分数,对于增加稳定性很重要;同时 KL 惩罚项()也很重要。
使用 AdamW 优化器(Loshchilov 和 Hutter,2017)来训练所有模型,其中,,。设定了 0.1 的权重衰减、1.0 的梯度裁剪以及 的恒定学习率。在每次 PPO 迭代中,使用 batch size=512、0.2 的 PPO 裁剪阈值、mini-batch size=64,并且每个mini-batch size进行一次梯度下降。对于 7B 和 13B 模型,设置(KL 惩罚),对于 34B 和 70B 模型,设置。
在训练过程中,您为所有模型进行了200到400次迭代,并使用保留的数据集进行early stopping。对于70B这样的大型模型,每次PPO迭代平均需要大约330秒。为了在大batch size下快速训练,我们使用了 FSDP(Zhao 等人,2023)。
FSDP通过跨多个GPU或节点分片模型参数和数据,实现了高效的并行计算,特别是在执行次前向或反向传播时效果显著。
3.3、用于多轮一致性的系统消息
3.3.1、问题背景
在对话设置中,某些指令应该适用于对话中的所有轮次,比如要求简洁回复,或者“扮演”某个公众人物。当我们向 LLaMA2-Chat 提供此类指令时,期望模型在后续的回应中始终遵循这些约束。然而,我们发现,在RLHF的初始模型中,模型往往在对话进行几轮后就忘记了初始的指令,如图9(左)所示。

为了解决上述模型在对话中忘记初始指令的局限性,我们提出了Ghost Attention(GAtt)方法。GAtt是一种受Context Distillation(Bai等人,2022b)启发的非常简单的方法,它通过修改微调数据来帮助注意力机制在多阶段过程中更好地聚焦。GAtt 实现了多轮对话控制,如图9(右)所示。
3.3.2、GAtt原理
假设我们能够获取到两个人(例如,用户和助手)之间的多轮对话数据集,包含一系列消息 ,其中 和 分别对应第 n 轮中用户和助手的消息。然后,我们定义一个贯穿整个对话都应遵循的指令inst,例如inst可以是“人设”。接着,我们可以将这个指令与对话中的所有用户消息进行合成拼接,生成。
使用最新一轮的RLHF模型对多轮中每个用户的消息生成多次的结果(此过程为采样),并使用RM选择最好的结果(llama2中提出的拒绝采样的步骤),这样就得到了符合指令的多轮对话数据。
针对合成的数据,删除除了第一轮用户消息以外的所有添加的指令,即;然后去sft训练模型。在训练过程中,多轮数据中前前几轮的所有损失设为0,不参与训练。
3.3.3、GATT评估
这段话似乎是在介绍关于 GAtt 的评估情况:
- 提到在 RLHF V3 之后应用了 GAtt 。
- 有定量分析表明 GAtt 在多达 20 多个回合内都能保持一致性,直到达到最大上下文长度(具体可参考附录 A.3.5 )。
- 尝试在推理时设置 GAtt 训练中不存在的约束,例如“始终用俳句回答”,模型在这种情况下仍保持一致,相关示例在附录图 28 中有说明。

为了说明GAtt在微调过程中如何重塑注意力,我们在图10中展示了模型的最大注意力激活情况。图中每一部分的左侧对应系统消息(“扮演奥斯卡·王尔德”)。可以看到,与没有GAtt的模型(左侧)相比,配备GAtt的模型(右侧)在对话过程中,对系统消息保持了较高的注意力激活。

3.4、RLHF Results
3.4.1、Model-Based Evaluation
评估大语言模型是一个具有挑战性的开放性研究问题。虽然人工评估是黄金标准,但它可能会受到各种人机交互因素的影响(Clark 等人,2021;Gehrmann 等人,2023),并且并不总是具有可扩展性。因此,为了在从 RLHF-V1 到 V5 的每次迭代中从多个消融实验中选择性能最佳的模型,我们首先观察最新奖励模型的奖励提升情况,以节省成本并提高迭代速度。随后,我们通过人工评估对主要模型版本进行了验证。
3.4.2、Human Evaluation
人工评估通常被认为是评判自然语言生成模型(包括对话模型)的黄金标准。为了评估主要模型版本的质量,我们让人工评估者对它们的有用性和安全性进行评分。我们在 4000 多个单轮和多轮提示上,将 Llama 2-Chat 模型与开源模型(Falcon、MPT、MosaicML NLP 团队等人,2023;Vicuna、Chiang 等人,2023)以及闭源模型(ChatGPT、OpenAI,2023;PaLM、Anil 等人,2023)进行比较。对于 ChatGPT,我们在所有生成中使用 gpt-3.5-turbo-0301 模型。对于 PaLM,我们在所有生成中使用 chat-bison-001 模型。每个模型的人工评估最终提示数量如表 32 所示。更多方法细节见附录 A.3.7 节。以下部分展示有用性结果;安全性结果在 4.4 节中呈现。

结果。如图 12 所示,Llama 2-Chat 模型在单轮和多轮提示上均显著优于开源模型。特别是,Llama 2-Chat 7B 模型在 60% 的提示上优于 MPT-7B-chat。Llama 2-Chat 34B 与同等规模的 Vicuna-33B 和 Falcon 40B 模型相比,总体胜率超过 75%。最大的 Llama 2-Chat 模型与 ChatGPT 具有竞争力。Llama 2-Chat 70B 模型相对于 ChatGPT 的胜率为 36%,平局率为 31.5%。Llama 2-Chat 70B 模型在我们的提示集上比 PaLM-bison 聊天模型的胜率高得多。更多结果和分析见 A.3.7 节。

评分者间信度(IRR)。在我们的人工评估中,三名不同的注释者对每个模型生成的比较提供独立评估。从数据质量的角度来看,高 IRR 分数(越接近 1.0 越好)通常被认为更好,但具体情况也很重要。像评估大语言模型生成的总体有用性这样高度主观的任务,其 IRR 分数通常会比更客观的标注任务低。在这些情况下,公开的基准测试相对较少,所以我们觉得在这里分享我们的分析将对研究社区有所帮助。
我们使用 Gwet 的 AC1/2 统计量(Gwet,2008 年,2014 年)来衡量评分者间信度(IRR),因为我们发现它在不同的测量场景中是最稳定的指标。在我们分析中使用的 7-point Likert scale 有用性任务中,Gwet 的 AC2 分数在 0.37 到 0.55 之间变化,具体取决于具体的模型比较。我们在胜率相似的模型比较(如 Llama 2-Chat-70B-chat 与 ChatGPT 的比较)的评分中看到该范围较低端的分数。在有更明显赢家的模型比较(如 Llama 2-Chat-34b-chat 与 Falcon-40b-instruct 的比较)的评分中看到该范围较高端的分数。
人工评估的局限性。虽然我们的结果表明 Llama 2-Chat 在人工评估中与 ChatGPT 相当,但需要注意的是,人工评估存在一些局限性。
- 按照学术和研究标准,我们有一个包含 4000 个提示的大型提示集。然而,它并没有涵盖这些模型在现实世界中的使用情况,而现实世界的使用情况可能涉及大量更多的用例。
- 提示的多样性可能是影响我们结果的另一个因素。例如,我们的提示集不包括任何与编码或推理相关的提示。
- 我们只评估多轮对话的最终生成结果。一个更有趣的评估方式可能是让模型完成一项任务,并对多轮对话中使用模型的整体体验进行评分。
- 对生成模型的人工评估本质上是主观且有噪声的。因此,在不同的提示集上或使用不同的指令进行评估可能会导致不同的结果。
4、Safety(略)
警告:本节包含可能被视为不安全、冒犯性或令人不安的文本示例。
在本节中,我们将深入探讨安全评估和风险管理这个重要话题。我们首先讨论对预训练数据和预训练模型展开的安全调查(4.1节)。接着,我们描述安全对齐的过程(4.2节),解释如何收集与安全相关的标注数据,如何使用监督微调(SFT)和基于人类反馈的强化学习(RLHF)方法,还会展示相关的实验结果。我们会讨论为了进一步了解和提高模型安全性而进行的红队测试(见 4.3 节)。最后,我们给出Llama 2-Chat的定量安全评估(4.4节)。我们还在附录的表52中提供了模型信息卡。
5、讨论
在此,我们讨论在基于人类反馈的强化学习(RLHF)过程中观察到的有趣特性(5.1 节),接着探讨 Llama 2-Chat 的局限性(5.2 节),最后阐述我们负责任地发布这些模型的策略(5.3 节)。
5.1、新发现与评论(Learnings and Observations)
我们的调优过程揭示了一些有趣的结果,例如 Llama 2-Chat 能够按时间组织知识,以及调用应用程序编程接口(API)来使用外部工具。
5.1.1、超越人类监督:从 SFT 到 RLHF
在项目开始时,我们中的许多人都倾向于使用有监督标注(supervised annotation)。 同时,强化学习(reinforcement learning)的不稳定性已经众所周知, 因此自然语言处理领域对其还是抱有一种怀疑态度。 但事实证明强化学习非常有效,尤其是考虑到其成本和时间效率。 我们的研究结果认为,
- RLHF 成功的关键是它在 标注过程中促进了人和 LLM 之间的协同(the synergy it fosters between humans and LLMs)。
- 即使是熟练的标注员,每个人的标注(书写)风格也存在显著差异。经过 SFT 标注微调出来的模型 学习到了这种多样性 —— 不幸的是,这包括那些标注质量很差的长尾部分。
- 模型性能受限于最熟练的标注员的能力。
当比较两个回答哪个更好时,人类标注员的判断基本上都是一致的。 因此,奖励机制迅速会将低分分配给质量差的尾部,并朝着人类偏好对齐。 这一现象在图 20 中有所体现,可以看到经过几轮迭代,最差的答案逐渐被移除,使分布向右移动。

图 20:随着 LLaMA2-Chat 的不断迭代(从 SFT 到 RLHF),奖励分布逐渐朝着高分漂移(distribution shift)。
此外,在标注过程中,模型可能生成比最优秀的标注员还要好的响应。 但当比较两个回答时,类在比较两个答案时,仍能提供超出自身写作能力的有价值反馈。打个比方,虽然我们并非都是技艺精湛的艺术家,但我们欣赏和评论艺术的能力依然存在。 我们认为,LLM 在某些任务中超越人类标注员的卓越写作能力, 基本上是由 RLHF 驱动的,Gilardi 等人(2023)和 Huang 等人(2023)之前也已经提到这一点。
监督式数据可能不再是黄金标准,这种不断变化的情况促使我们重新评估 “监督” 的概念。
5.1.2、上下文温度动态调整
我们观察到了一个与基于人类反馈的强化学习相关的有趣现象,据我们所知,此前尚未有相关报道:温度会根据上下文进行动态调整。如图 8 所示,温度似乎受到基于人类反馈的强化学习的影响。然而,有趣的是,我们的研究结果还显示,这种变化并非在所有提示中均匀应用,如图 21 所示。例如,对于与创造力相关的提示,如 “写一首诗”,在我们的各种基于人类反馈的强化学习迭代中,温度的升高会持续产生多样化的结果。这可以从自 BLEU(Self-BLEU)斜率中观察到,它与监督式微调模型的模式相似。另一方面,对于基于事实信息的提示,如 “[国家名称] 的首都是什么?”,随着时间的推移,自 BLEU 斜率会减小。这一模式表明,尽管温度在升高,但模型学会了对事实性提示始终提供相同的回答。

5.1.3、LLaMA2-Chat 时间感知能力(Temporal Perception)
我们的模型展现出了令人印象深刻的泛化能力,如图 22 所示。我们手动测试了数十个例子,始终观察到即使在数据极少的情况下,我们的模型也能稳健地以时间顺序组织知识。为了在 Llama 2-Chat 中植入时间概念,我们收集了 1000 个与特定日期相关的监督微调(SFT)示例。这些示例包含诸如 “巴拉克・奥巴马当选总统距今有多久?” 这类问题。每个问题都关联着两个关键的元数据:提出查询的日期(这会影响回答内容)和事件发生的日期(在该日期之前,这个问题毫无意义 )。

这一观察结果表明,大语言模型(LLMs)对时间概念的内化程度比之前认为的更高,尽管它们的训练仅仅基于下一个词元预测,且所使用的数据是随机打乱的,并未考虑时间顺序。
5.1.4、工具的使用
OpenAI 插件的发布在学术界引发了广泛讨论,引发了诸如 “我们如何有效地教会模型使用工具?” 以及 “这个过程是否需要大量数据集?” 等问题。我们的实验表明,工具使用能力可以通过对齐以零样本的方式自然涌现。尽管我们从未明确对工具使用进行注释,但图 23 展示了一个例子,模型在零样本的情境下展现出了使用一系列工具的能力。

在图 23 的例子中,任务是比较鲨鱼和树木首次出现在地球上的时间。模型能够理解任务需求,通过调用名为 “SEARCH” 的 API 获取鲨鱼和树木首次出现的时间信息,然后调用 “CALCULATOR” 进行计算,最终得出鲨鱼比树木早约 6500 万年出现在地球上的结论。这表明 Llama 2-Chat 能够仅通过语义理解工具的应用和 API 参数,尽管它从未接受过使用工具的训练。
此外,我们的研究还扩展到评估接入计算器的 Llama 2-Chat 的能力。这项特定实验的结果记录在表 15 中。虽然大语言模型使用工具令人兴奋,但也引发了一些安全问题。我们鼓励社区在这一领域开展更多研究和红队测试。

5.2、限制和伦理考虑
Llama 2-Chat和其他大语言模型一样,存在一些公认的局限性。包括在预训练后知识无法更新,可能产生如不恰当建议等非事实性内容,以及容易出现幻觉等问题。
此外,我们最初版本的Llama 2-Chat主要聚焦于英语数据。虽然实验观察表明该模型在其他语言上也有一定的能力,但由于非英语语言的预训练数据有限(如表10所示),其在这些语言上的表现仍然欠佳,使用时应格外谨慎。
与其他大语言模型类似,Llama 2可能会因为在公开的在线数据集上进行训练,而生成有害、冒犯性或带有偏见的内容。我们试图通过微调来缓解这些问题,但对于那些没有公开可用数据集的非英语语言来说,一些问题可能依然存在。随着我们在解决这些问题上不断取得进展,未来我们会继续对模型进行微调并发布更新版本。
坏人也可能使用 AI 模型,对话式人工智能代理可能会被用于恶意目的,比如生成错误信息,或者获取有关生物恐怖主义、网络犯罪等方面的信息。不过,我们已努力对模型进行调整,使其避免涉及这些话题,并削弱模型在这些方面的能力。
虽然我们试图在安全性和实用性之间找到合理的平衡,但在某些情况下,我们的安全调整可能会过度。Llama 2-Chat的用户可能会发现,模型在处理某些请求时过于谨慎,要么倾向于拒绝某些请求,要么在回应中提供过多的安全提示。
预训练模型的用户需要格外小心,应按照我们的《负责任使用指南》,在模型调优和部署过程中采取额外措施。
5.3、负责任的发布策略(Responsible Release Strategy)
5.3.1、发布细节
LLaMA2 允许用于研究和商业用途。 使用 LLaMA2 的人必须遵守其许可证和我们的 Acceptable Use Policy,禁止任何违反政策、法律、规则和法规的用途。
我们还提供了代码示例,以帮助开发者重复我们在 LLaMA2-Chat 中的 safe generations, 以及在用户输入和模型输出层应用(apply)一些基础安全技术。
最后,我们提供了一份“负责任使用指南”(Responsible Use Guide), 里面有关于安全开发和部署(safe development and deployment)的指导原则。
5.3.2、负责任的发布
虽然许多公司选择在封闭环境中开发人工智能,但我们公开发布 Llama 2,以鼓励负责任的人工智能创新。根据我们的经验,开放的方式能够汲取人工智能从业者社区的集体智慧、多样性和创造力,从而实现这项技术的价值。通过合作,可以让这些模型变得更好、更安全。整个人工智能社区,包括学术研究人员、民间社会、政策制定者和行业从业者,必须共同努力,严格分析和揭示当前人工智能系统的风险,并构建解决方案来应对可能出现的不当使用问题。这种方法不仅促进了与各方利益相关者(不仅仅是大型科技公司内部人员)的真正合作,也为普及基础模型的使用奠定了基础。正如泽勒斯等人(2019 年 b)所主张的,开放发布能够提高透明度,让更多人接触到人工智能工具,实现技术的民主化,并分散人工智能专业知识。我们相信,人工智能专业知识的分散不仅能够传播知识,还能激发创新,加速行业的进步。最后,公开发布这些模型可以整合成本,消除进入壁垒,使小企业能够利用大语言模型的创新成果,探索和构建文本生成的应用场景。最终,我们相信这将为全球各种规模的组织创造一个更公平的竞争环境,让它们从人工智能进步带来的经济增长中受益。
5.3.3、开源风险
我们知道,并非所有使用人工智能模型的人都怀有善意,并且我们也承认,人们对人工智能将以何种方式影响我们的世界存在合理的担忧。生成有毒内容以及产生不良关联是人工智能领域尚未完全解决的重大风险。正如本文所阐述的,我们在减少这类回应的出现频率方面已经取得了进展。虽然我们认识到还有更多工作要做,但这一认知只会让我们更加坚定地致力于开放科学,并与人工智能领域的各方展开合作。
6、相关工作
6.1、大语言模型
近年来,大语言模型领域取得了重大进展。遵循卡普兰等人(2020年)提出的缩放定律,从GPT-3(布朗等人,2020年)到Gopher(雷等人,2022年),再到像Galactica这样用于科学领域的专用模型(泰勒等人,2022年),诸多参数超过1000亿的大语言模型相继问世。拥有700亿参数的Chinchilla(霍夫曼等人,2022年)将这些缩放定律的关注点重新定义为token数量,而非模型参数规模。在这一发展进程中,Llama脱颖而出,因其在推理过程中对计算效率的注重而受到关注(图沃伦等人,2023年)。与此同时,围绕开源与闭源模型的讨论也在展开。BLOOM(斯考等人,2022年)、OPT(张等人,2022年)和Falcon(佩内多等人,2023年)等开源模型,向GPT-3和Chinchilla等闭源模型发起了挑战。
然而,像ChatGPT、Bard和Claude这些 “可投入实际应用” 的大语言模型,在性能和可用性方面存在显著差异。这些模型依靠复杂的调优技术来契合人类偏好(古迪班德等人,2023年),而这一过程在开源社区仍处于探索和完善阶段。
为缩小这一差距,出现了一些尝试,如基于蒸馏的模型Vicuna(蒋等人,2023年)和Alpaca(陶里等人,2023年)采用了独特的方法,利用合成指令进行训练(霍诺维奇等人,2022年;王等人,2022年)。尽管这些模型展现出一定潜力,但与闭源模型相比,仍存在差距。
6.2、指令调整
魏等人(2021年)通过在众多数据集上对大语言模型进行微调,使其在未见任务上获得了零样本学习的能力。钟等人(2022年)和朗普雷等人(2023年)研究了指令调整在任务数量、模型大小、提示设置等方面的影响。用于指令调整的提示可以由人工创建,也可以由大语言模型自行生成(周等人,2022年),后续指令可用于优化初始生成结果,使其更有用、更具吸引力且更无偏见(甘古利等人,2023年;马丹等人,2023年)。与指令调整相关的一种方法是思维链提示(魏等人,2022年b),即当模型面对复杂问题时,促使其解释推理过程,以提高最终答案的正确性。
基于人类反馈的强化学习(RLHF)已成为微调大语言模型的有力策略,能显著提升模型性能(克里斯蒂亚诺等人,2017年)。该方法最早由斯泰农等人(2020年)在文本摘要任务中展示,此后已扩展到一系列其他应用领域。在这种范式中,模型根据人类用户的反馈进行微调,从而不断使模型的响应更符合人类的期望和偏好。
欧阳等人(2022年)证明,指令微调与基于人类反馈的强化学习相结合,有助于解决仅靠扩大模型规模无法解决的事实性、毒性和有用性问题。白等人(2022年b)通过用模型自身的自我批评和修订替代人工标注的微调数据,并在基于人类反馈的强化学习中用模型替代人类评估者对模型输出进行排序,实现了这种微调加基于人类反馈的强化学习方法的部分自动化,这一过程被称为 “基于人工智能反馈的强化学习”(RLAIF)。
6.3、已知的大语言模型安全挑战
近期的文献广泛探讨了与大语言模型相关的风险和挑战。本德等人(2021年b)和魏丁格等人(2021年)强调了各种危害,如偏差、毒性、私人数据泄露以及恶意使用的潜在风险。索莱曼等人(2023年)将这些影响分为两类——可在基础系统内评估的影响和需要在社会背景下评估的影响,而库马尔等人(2022年)则提出了潜在的缓解策略以减少危害。罗勒等人(2020年)和迪南等人(2021年)的研究也揭示了以聊天机器人为导向的大语言模型所面临的困难,
7、总结
本文介绍了 LLaMA2 —— 一组新的预训练和微调模型,参数规模从 7b 到 70b。 实验结果表明尽管 LLaMA2 仍然落后于 GPT-4 等最先进的模型, 这些与现有的开源聊天模型相比已经具有同等竞争力,在一些数据集上与某些专有模型的能力相当。
本文详细阐述了实现 LLaMA2 所用的方法和技术,并重点如何与 helpfulness and safety 原则对齐。 为更有意义地为社会做出贡献并促进研究步伐,我们负责任地开放了 LLaMA2 和 LLaMA2-Chat。 对透明度和安全性的持续承诺,将使我们在未来工作中进一步改进 LLaMA2-Chat。
参考文献(略)
附录(略)
« [译][论文] 大语言模型(LLM)综述与实用指南(Amazon,2023) Understanding NVIDIA GPU Performance: Utilization vs. Saturation (2023) »