type
Post
status
Published
password
date
slug
summary
category
tags
icon
深度学习中与分类相关的问题都会涉及到softmax的计算。当目标类别较少时,直接用标准的softmax公式进行计算没问题,当目标类别特别多时,则需采用估算近似的方法简化softmax中归一化的计算。
以自然语言中的语言模型为例,从理论到实践详解基于采样的softmax的近似方法NCE。
1、理论回顾
逻辑回归和softmax回归是两个基础的分类模型,它们都属于线性模型。前者主要处理二分类问题,后者主要处理多分类问题。事实上softmax回归是逻辑回归的一般形式。
1.1、Logistic Regression
逻辑回归的模型(函数/假设)为:
其中为sigmoid函数,为模型输入,为模型参数,为模型预测输入为正样本(类别为1)的概率,而为输入对应的真实类别(只有类别0与类别1两种)。其对应的损失函数如下:
上述损失函数称为交叉熵(cross-entropy)损失,也叫log损失。通过优化算法(SGD/Adam)极小化该损失函数,可确定模型参数。
1.2、Softmax Regression
softmax回归的模型(函数/假设)为:
其中为模型参数,表示第个样本输入属于各个类别的概率,且所有概率和为1。其对应的损失函数如下:
其中表示第个样本的标签值是否等于第个类别,等于的话为1,否则为0。该损失函数与逻辑回归的具有相同的形式,都是对概率取对数后与实际类别的one-hot编码进行逐位相乘再求和的操作,最后记得加个负号。
2、Noise Contrastive Estimation
2.1、背景
由上述softmax的假设函数可知,在学习阶段,每进行一个样本的类别估计都需要计算其属于各个类别的得分并归一化为概率值。当类别数特别大时,如语言模型中从海量词表中预测下一个词(词表中词即这里的类别)。用标准的softmax进行预测就会出现瓶颈。
是基于采样的方法,将多分类问题转为二分类问题。以语言模型为例,利用可将从词表中预测某个词的多分类问题,转为从噪音词中区分出目标词的二分类问题。具体如图所示:
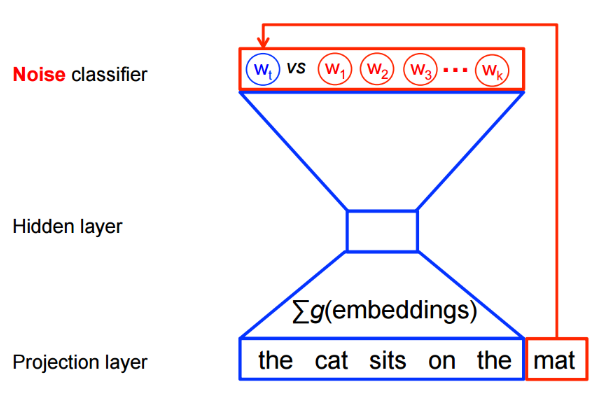
2.2、损失函数
下面从数学角度看看具体如何构造转化后的目标函数(损失函数)
记词的上下文为,为从某种噪音分布中生成的个噪音词(从词表中采样生成)。则构成了正样本(),构成了负样本()。
基于上述描述,可用逻辑回归模型构造如下损失函数:
上述损失函数中共有个样本。可看成从两种不同的分布中分别采样得到的,一个是依据训练集的经验分布每次从词表中采样一个目标样本,其依赖于上下文;而另一个是依据噪音分布每次从词表中采样个噪音样本(不包括目标样本)。基于上述两种分布,有如下混合分布时的采样概率:
更进一步地,有
其中为待学习的参数(包括模型的参数)。
又
其中为词的输出embedding。(为词的输入embedding,两个都是待学习的参数)
从定义可知,我们在处理每个样本时仍需对词表中的个词进行归一化操作。而NCE将中需要归一化的分母处理成可学习的参数,从而避免大量的计算。 从实际学习的数值看,每次分母的数值接近1且有较低的方差,实际操作时,可直接设为1。 此时可进一步简化为
则最终正样本的概率为
等价于逻辑回归中的。
由逻辑回归的损失函数可得最终NCE的损失函数为:
备注:NCE具有很好的理论保证:随着噪音样本数的增加,NCE的导数趋向于softmax的梯度。 有研究证明25个噪音样本足以匹配常规softmax的性能,且有的加速。
3、Negative Sampling
负采样(NEG)可看成是NCE的近似估计,其并不保证趋向于softmax。因为NEG的目标是学习高质量的词表示,而不是语言模型中的低困惑度(perplexity)。
负采样与NCE一样,也是以逻辑回归的损失函数为目标进行学习的。主要的区别在于将原先NCE的正样本概率表达式
进一步简化为
当是均匀分布(每个词等概率出现)且时,成立,此时,NCE与NEG等价。其他情况,只是近似。
至于为何设成1而不是其他常数,因为可将简化后的概率表达式进一步写成形式:
其他分析流程与NCE相同,不在赘述。
4、InfoNCE
考虑编码后的查询 和一组作为字典键的编码样本 ,假设字典中仅有一个正样本键 与 匹配。对比损失要求 与 相似,而与其他负样本键不同。本文采用InfoNCE损失:
其中 为温度超参数,求和包括1个正样本和 个负样本。对比损失作为无监督目标函数,用于训练表示查询和键的编码器网络。一般来说,查询表示为 ,键表示为 ,具体取决于 pretext 任务。输入 和 可以是图像、patches或patches集合,编码器 和 可以相同、部分共享或不同。