type
Post
status
Published
password
date
Jul 18, 2024
slug
summary
category
人工智能
tags
LLM
icon
旋转位置编码(Rotary Position Embedding,RoPE)是论文Roformer: Enhanced Transformer With Rotray Position Embedding 提出的一种能够将相对位置信息依赖集成到 self-attention 中并提升 transformer 架构性能的位置编码方式。RoPE 具有更好的外推性,目前是大模型相对位置编码中应用最广的方式之一。
外推性是指大模型在训练时和预测时的输入长度不一致,导致模型的泛化能力下降的问题。例如,如果一个模型在训练时只使用了512个 token 的文本,那么在预测时如果输入超过512个 token,模型可能无法正确处理。这就限制了大模型在处理长文本或多轮对话等任务时的效果。
背景
Transformer为什么需要位置编码
attention公式
为什么需要位置编码
为什么需要位置编码
统一公式
- 是输入向量。token的隐藏向量
- 是位置索引。与token的位置索引有关
- 是频率参数。与token隐藏向量的维度有关
- 和 是可调函数,分别描述位置和频率的变换逻辑。
固定位置编码
绝对位置编码
其中, 表示单词在句子中的位置, 表示 PE 的维度 (与词 Embedding 一样), 表示偶数的维度, 表示奇数维度 (即 , )。
可学习的位置编码
是一个可以学习的矩阵,例如Bert模型中的编码方式
旋转编码 RoPE
原理
RoPE通过绝对位置编码的方式实现相对位置编码,综合了绝对位置编码和相对位置编码的优点。计算与相似度的时候,只依赖token向量与token之间的相对位置。
二维推导
此时,、只有两个维度。

扩展到多维(带入了不同的)
将2维推广到任意维度,可以表示如下:
其中可以表示为任意二维情形的拼接,的下脚标表示第个token。
原理图解
”Enhanced”的word embedding先乘以和得到query和key,这两个向量都是维的。然后把它切分成个二维向量,比如图中最前面绿色的。然后用旋转矩阵得到,这里Enhanced是第一个token,所以。用类似的方法可以得到query和key的第3~4,第5~6,…,第维的向量。也就是图中右边的Position Encoded Query/Key。
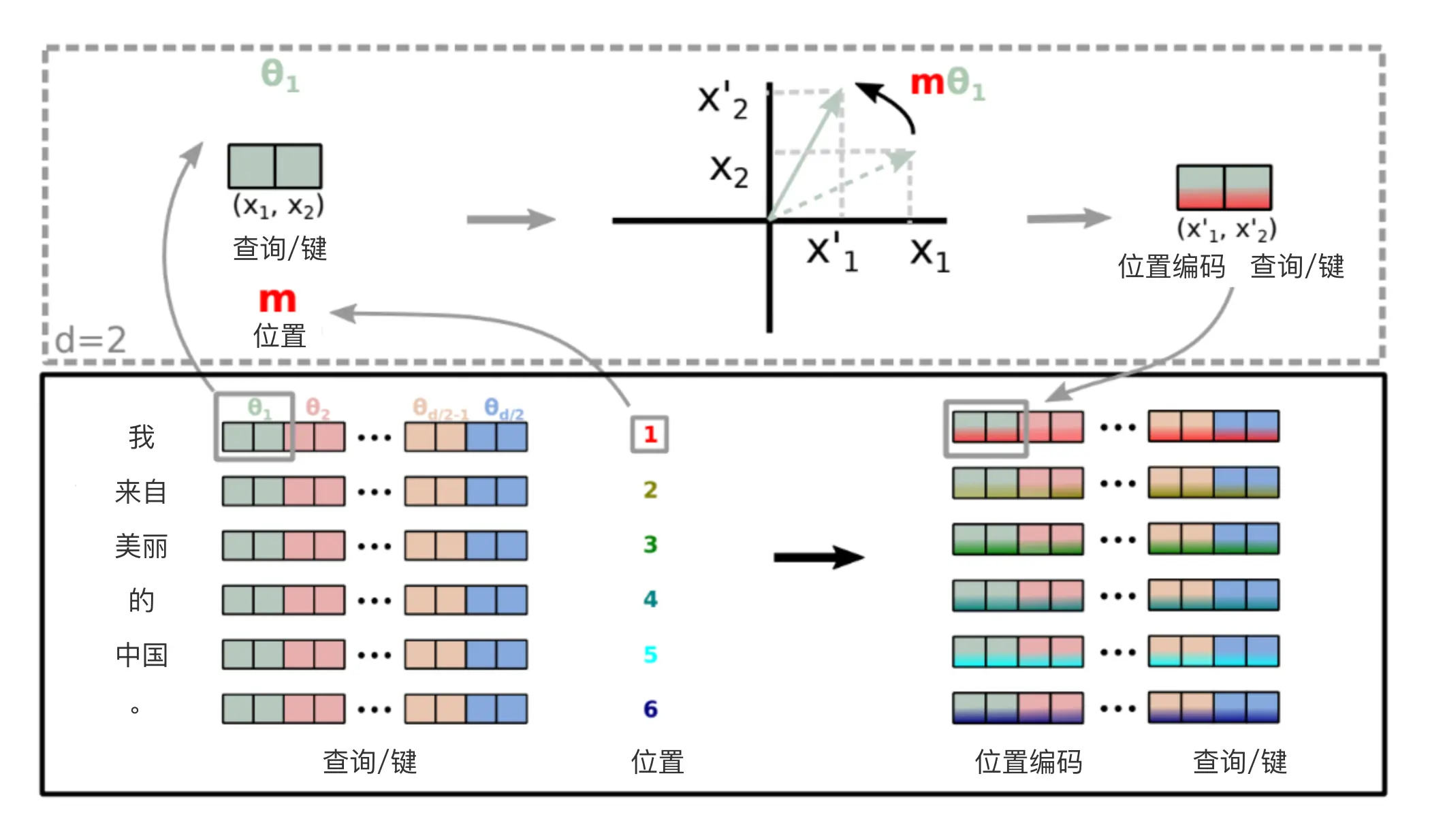

- 旋转角度
这里 完全由 Q、K、V 的向量长度 决定,即 dim
- 位置 Position m:单词对应的位置
- Freq 频次矩阵:结合上面的信息,针对一个固定了长度 m 和向量维度 d 的 LLM,我们可以提前将其对应的旋转变换矩阵构造完成:
结合 Rd 的变换矩阵,分别执行 cos 和 sin,便可以得到我们计算所需的全位置全维度的变换矩阵。下面看下代码如何实现。
RoPE 的高效计算
对于第m个token。

由于的稀疏性,所以直接用矩阵乘法来实现会很浪费算力,推荐通过下述方式来实现 RoPE:
其中是逐位对应相乘,其中表示第个token。
RoPE性质
远程衰减
RoPE(旋转位置编码)的远程衰减性指的是,对于两个词向量,如果它们的相对距离较近,那么它们的注意力分数应该偏高,反之应该偏低。即随着词向量之间相对距离的增大,它们的注意力得分会逐渐衰减。
在RoPE中,作者沿用了Sinusoidal位置编码的方案,即 ,其中 表示词向量的维度。这种方案会带来一定的远程衰减性,使得模型能够更好地捕捉词向量之间的相对位置关系。

从图中我们可以看到随着相对距离的变大,内积结果有衰减趋势的出现。因此,选择 ,确实能带来一定的远程衰减性。论文中还试过以 为初始化,将 视为可训练参数,然后训练一段时间后发现 并没有显著更新,因此干脆就直接固定了。
RoPE的外推性
RoPE 可以通过旋转矩阵来实现位置编码的外推,即可以通过旋转矩阵来生成超过预期训练长度的位置编码。这样可以提高模型的泛化能力和鲁棒性。
旋转角度
- 低维度(即值较小的维度):更接近于1(),此时的变化较大,旋转更快
- 高维度(即值较大的维度):更接近于0(),此时的变化较小,旋转更慢
因此低维度具有更快的旋转(对应局部细节捕捉),高维度具有更慢的旋转(对应长距离依赖)。这种设计巧妙地结合了长距离和短距离的信息编码能力。
RoPE代码实现
Meta 的 LLAMA 和 清华的 ChatGLM 都使用了 RoPE 编码,下面看一下具体实现。

在LLAMA中的实现
这里举一个例子,假设batch_size=10, seq_len=3, d=8,则调用函数precompute_freqs_cis(d, seq_len)后,生成结果为:
在ChatGLM中的实现
和 LLAMA 的实现方式相差不大。代码如下:
旋转位置嵌入 (ROPE) (labml.ai)
RoPE实验
Max seq length | Batch size | Training steps | Loss | Accuracy |
512 | 256 | 200k | 1.73 | 65.0% |
1536 | 256 | 12.5k | 1.61 | 66.8% |
256 | 256 | 120k | 1.75 | 64.6% |
1536 | 256 | 10k | 1.58 | 67.4% |
128 | 512 | 80k | 1.83 | 63.4% |
512 | 512 | 30k | 1.66 | 66.2% |
从上面可以看出,增大序列长度,预训练的准确率反而有所提升,这体现了 RoPE 具有良好的外推能力。
下面是在下游任务上的实验结果:
Model | Validation | Test |
BERT-512 | 64.13% | 67.77% |
WoBERT-512 | 64.07% | 68.10% |
RoFormer-512 | 64.13% | 68.29% |
RoFormer-1024 | 66.07% | 69.79% |
其中 RoFormer 是一个绝对位置编码替换为 RoPE 的WoBERT模型,后面的参数(512)是微调时截断的maxlen,可以看到 RoPE 确实能较好地处理长文本语义。
总结
旋转编码 RoPE 具有远程衰减,即随着词向量之间相对距离的增大,它们的注意力得分会逐渐衰减。
旋转编码 RoPE 可以通过旋转矩阵来实现位置编码的外推,即可以通过旋转矩阵来生成超过预训练长度的位置编码。这样可以提高模型的泛化能力和鲁棒性。
旋转编码 RoPE 可以与线性注意力机制兼容,即不需要额外的计算或参数来实现相对位置编码。这样可以降低模型的计算复杂度和内存消耗。这一点是其他混合位置编码方式(如Transformer-XL、XLNet等)所不具备的,因为它们需要额外的计算或参数来实现相对位置编码。
位置编码扩展
Position Interpolation (PI):线性插值

PI尝试通过重新定义通过线性缩小输入位置索引以匹配原始上下文窗口大小,而不是超出训练上下文长度进行外推:
- ,其中 是上下文扩展比例。
- ,保持频率参数不变。
这使得每个位置索引被均匀拉伸到预训练窗口内,公式变为:
- 效果:在从 LLaMA 7B 到 65B 模型上,通过位置插值扩展上下文窗口到 32768(4k扩展到32K),仅需微调 1000 步,就能在包括语言建模、长文档摘要撰写等任务上取得良好效果。
- 优点:简单有效,训练开销小。
- 缺点:需要重新训练,有时候扩充后会导致模型困惑度上升。
NTK-Aware Interpolation:动态插值
背景
在原始的 ROPE 中,旋转角度,其中10000是基数,是维度索引,是模型维度。当使用位置插值(PI)方法扩展上下文窗口时,PI 会将位置索引除以扩展比,即把每个位置均匀压缩为之前的。这会导致所有维度的旋转角度都变为原来的,平等对待所有维度,没有考虑不同维度的特性。由于旋转角度随着维度增加呈指数级减小,低维(高频)部分的旋转角度相对高维(低频)部分,变化更大,旋转更快,使得低维(高频)信息变得拥挤,造成高频信息损失。
我们知道位置通过进行编码,其中代表位置,代表基础频率。既然我们能够通过缩放,进行上下文扩展;我们也可以通过缩放,实现上下文扩展。
原理
NTK-aware RoPE对所有维度采用非均匀缩放,对于高频(低维)部分缩放程度小一点,进行小幅度插值,甚至保持不变;对于低频(高维)部分缩放程度大一点,进行更大幅度地插值。
- 时,,有没有 都不影响,因此也叫直接外推。
- 时,,变成了线性内插。
所以该方法可以理解为介于直接外推和线性内插之间的平滑方法。 它主要对高维度更大幅度地插值;低维,进行小幅度插值,甚至保持不变。
- 优点:在未微调模型中显著提升长文本建模能力。
- 缺点:部分频率超出预训练范围,可能引发性能不稳定。
NTK-by-parts Interpolation
NTK - by - parts是在NTK - aware基础上,对embedding的不同维度进一步区别对待的一种方法。通过这种对不同维度根据其波长与上下文长度的关系进行不同处理的方式,更好地利用了位置编码中的信息,在扩展上下文窗口时能更有针对性地处理不同频率的信息,减少对模型性能的影响。
波长概念
在RoPE中,给定一个具体维度,其波长被定义为。波长描述了为在维度处嵌入的旋转位置执行全旋转()所需的token长度,且维度越高波长越长。如果某些维度的波长大于上下文长度,这说明该维度无法执行全旋转。在这种情况下,由于维度在预训练期间至少不会完全旋转一次,如果我们选择第一个令牌作为基准,那么在预训练期间每隔一个令牌到它的距离是唯一的,神经网络可以用它来确定它的绝对位置信息。相反,如果某个维度波长小于,那该维度就执行了至少一次全旋转,我们就无法在这个维度描述绝对距离,只能描述相对位置信息。
不同维度处理策略
- 不内插情况:如果当前维度的波长远小于上下文长度(如小于),说明该维度在预训练期间旋转很多圈,主要编码相对位置信息,对模型区分附近token的相对顺序至关重要,因此不对其进行内插,即。
- 内插情况:当波长大于等于上下文长度时,该维度在预训练期间无法完成一次全旋转,主要编码绝对位置信息,没有超出绝对位置的最大可编码范围,需要进行内插,此时,为缩放因子。
- 中间情况:波长介于上述两者之间的维度,则采用NTK - aware方法,即使用外推和插值的加权和。
数学表达
- ,保持位置索引不变
- ,根据维度的不同类别对频率参数进行相应的变换。
“NTK-by-parts”方法通过根据波长区分维度并采用不同插值策略,能够更好地平衡高频信息保留和位置关系理解,实验中可以表现的更好。关于参数取值逻辑可以参考DeepSeekV3: 和 。
Dynamic NTK
NTK-Aware Interpolation升级版。Dynamic Scaling在每次推理时,会根据当前输入序列的长度来动态地调整缩放比。对于自回归模型而言,其所处理的序列是不断变化的,每一步比前一步增加一个token。 在这种情况下有两种插值的方法
- 在整个推理阶段,使用固定的缩放因子, 其中是预测阶段文本长度
- 在每轮前向传播中,位置编码更新缩放因子, 其中是当前序列的长度
方案1的问题在于,当序列长度小于时,模型性能可能会有一点小折扣;而当序列长度大于时,模型性能则会突然下降,而使用方案2可以使模型性能下降的更少。论文中把方案二这种在推理阶段不断调整缩放因子的方式称为Dynamic Scaling
Yarn (NTK-aware + NTK-by-parts + Dynamic NTK)
YaRN是基于NTK-aware方法的进一步拓展,通过结合温度缩放和NTK-by-parts插值技术,全面提升长文本外推能力。它核心解决的问题是线性内插导致的self-attention点积的值增大。由于线性内插会改变旋转向量转动的幅度,原来距离较远的点积由于旋转幅度变小,他们的点积结果会增大,进而导致Softmax操作过于“锐化”,使得注意力分布集中于少数位置,削弱模型对全局上下文的关注能力。 Yarn在 NTK-by-parts 基础上,引入注意力温度因子来调整注意力分布:
二维位置编码
二维RoPE
一半的维度用于计算H、一半的维度用于计算W。下方公式中的h、w分别代表二维图像中的位置。d代表隐藏层维度
可学习的二维编码
相对位置编码矩阵直接加在了attention 矩阵中,注意的维度和attention矩阵相同,即seq_len x seq_len。
相对位置取决于参考点在哪,以一个2x2大小,共4个像素的图像为例,其相对位置信息有四种

参考
Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces
上一篇文章中,我们对原始的Sinusoidal位置编码做了较为详细的推导和理解,总的感觉是Sinusoidal位置编码是一种“想要成为相对位置编码的绝对位置编码”。一般来说,绝对位置编码具有实现...